I blame the tokenizer
To those that developed the tokenizer for the Llama-2 family of language models, I have a bone to pick with you.
So I’m procrastinating working on an extension of a paper that claims the Llama-2 family of models “think in English”.
They show that if you use logit lens1 during a forward
pass on a multi-shot translation prompt from, say, French to German, internally the model assigns a high probability
to the corresponding English word. That’s very curious!
I want to query meta-llama/llama-2-7b-hf with a large amount of responses of the form
Français: " jour" - Deutsch: " Tag"
Français: " homme" - Deutsch: " Mann"
Français: " cinq" - Deutsch: " fünf"
Français: " nouveau" - Deutsch: " neu"
Français: " livre" - Deutsch: "
The model receives pairs of identical words in French and German (e.g jour and Tag mean day in French and German respectively),
so naturally the next thing it should guess is Buch (book), and it does, because models are good at learning in-context.
That works, but I have lots of examples, and I want to run them in bulk. I note that all the prompt share the same prefix
Français: " jour" - Deutsch: " Tag"
Français: " homme" - Deutsch: " Mann"
Français: " cinq" - Deutsch: " fünf"
Français: " nouveau" - Deutsch: " neu"
Français: "
and all the suffixes are of the form2
livre" Deutsch: "
nuage" Deutsch: "
sac" Deutsch: "
montagne" Deutsch: "
tissu" Deutsch: "
Future words cannot change the predictions for past words due to causal masking, so we can run the model on the common prefix, cache the activations for keys and values, and then do a batched run on all the suffixes together. Problem is that not all suffixes will tokenize to the same number of tokens, so I can’t just stack them in a matrix and read the last column, as a matrix cannot have variable length rows.
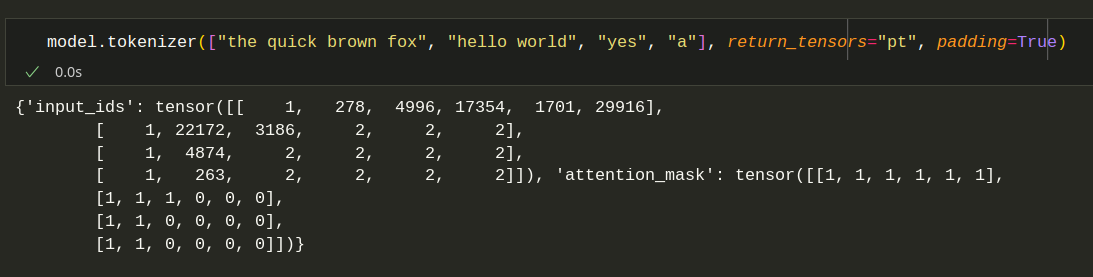
Okay, no problem, we can tokenize in bulk, and get it to just pad out the shorter sequences with a dummy token, and the tokenizer will tell me with the attention mask which ones are actually important.
For example, the string "the quick brown fox" gets tokenized as [1, 278, 4996, 17354, 1701, 29916] and "a" becomes [1, 263] which gets padded to [1, 263, 2, 2, 2, 2]. We can then sum the rows of the attention mask to get the length of each sequence, and use this to index into the output logits3 to get the prediction for the next token, for each suffix.
This keeps the GPU busy as I can now run inference on many sequences in a big batch rather than for-looping on each row, and I can sum the rows in the attention mask to pick out the prediction I want. So far, so good.
from collections import namedtuple
TokenizedSuffixesResult = namedtuple('TokenizedSuffixesResult',
['input_ids', 'attention_mask', 'indices'],
defaults=[None, None, None])
def tokenize_suffixes(suffixes : List[str], model):
device = next(model.parameters()).device
model.tokenizer.pad_token = model.tokenizer.eos_token
suffix_tokens, attn_mask = model.tokenizer(suffixes,
add_special_tokens=False,
return_tensors="pt",
padding=True).values()
indices = attn_mask.sum(dim=1)-1
assert torch.all(indices >= 0), "Attention mask has zeros, empty suffixes"
suffix_tokens = suffix_tokens.to(device)
return TokenizedSuffixesResult(
input_ids=suffix_tokens,
attention_mask=attn_mask,
indices=indices
)
llama-2 likes to put a special reserved start-of-sequence token <s> with token id 1 at the
start of each sequence. Good for a prompt, bad for a suffix of a prompt. No worries, use add_special_tokens=False for the tokenizer.
BUT for some inexplicable reason, it also likes to prepend a space character to every sequence BEFORE tokenizing.
For example, see the difference between tokenizing hellohello, for which the first hello gets (silently) preprocessed as ▁hello and tokenized as 22172 and the second hello gets tokenized as hello (token id 12199), versus tokenizing the emoji 🌍, which gets preprocessed as ▁🌍, the space character does not bind to the earth emoji, and the result is tokenized as 29871,31494 i.e. the space token ▁ with id 29871, followed by the earth token 🌍 with id 31494. You can play with the tokenizer here.
Okay, sure, just slice out the first column. But due to tokenizer shenanigans, depending on what the first word is,
the space might bind to it and tokenize as ▁hello, or sometimes seperately as ▁ world. The model internally
learns to do this based on the data it’s seen: some words have spaces in front, some don’t, and it’s learned to tokenize
based on that.
So, shit, I can’t just slice it out. So, I need to find something I can add to the front that will never bind to a space. So I search through all 50k tokens in the
vocabulary, and by happenstance 🌍4 is a single token with token id 31494, as opposed to a sequence of utf-8 encoded bytes, which is typical for emojis.
Example for 😂
For example, 😂 (ignoring for a moment the leading padding space) gets tokenized as243, 162, 155, 133, which (almost!) matches the utf-8 encoding.
>>> bytes = "😂".encode("utf-8")
>>> [int(x) for x in bytes]
[240, 159, 152, 130]
<unk> for unknown,
<s> for beginning and </s> for end of text tokens, and shuffled everything else down.
We can see this by running
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
vocab = tokenizer.get_vocab()
sorted_vocab = sorted(vocab.items(), key=lambda x: x[1])
for token, id in sorted_vocab[:10]:
print(f"Token: {token}, ID: {id}")
Token: <unk>, ID: 0
Token: <s>, ID: 1
Token: </s>, ID: 2
Token: <0x00>, ID: 3
Token: <0x01>, ID: 4
Token: <0x02>, ID: 5
Token: <0x03>, ID: 6
Token: <0x04>, ID: 7
Token: <0x05>, ID: 8
Token: <0x06>, ID: 9
Ergo, I present to you my hacky solution, for which the emoji 🌍 is critical, and it WILL NOT WORK with a different choice of emoji5.
def safe_tokenize(suffixes : List[str] | str,
model : HookedTransformer
) -> TokenizedSuffixesResult:
device = next(model.parameters()).device
model.tokenizer.pad_token = model.tokenizer.eos_token
if isinstance(suffixes, str):
suffixes = [suffixes]
if "Llama-2" in model.tokenizer.name_or_path:
suffixes = ["🌍" + x for x in suffixes]
space_token_id = model.tokenizer.convert_tokens_to_ids("▁")
earth_token_id = model.tokenizer.convert_tokens_to_ids("🌍")
suffix_tokens, attn_mask = model.tokenizer(suffixes,
add_special_tokens=False,
return_tensors="pt",
padding=True).values()
assert torch.all(suffix_tokens[:, 0] == space_token_id), "llama2 has leading space token"
assert torch.all(suffix_tokens[:, 1] == earth_token_id), "llama2 single token for 🌍"
suffix_tokens = suffix_tokens[:, 2:]
attn_mask = attn_mask[:, 2:]
idx = attn_mask.sum(dim=-1) - 1 #-1, and another two more: one for the space token, one for the 🌍 token
else: # models that do not add leading spaces
suffix_tokens, attn_mask = model.tokenizer(suffixes,
add_special_tokens=False,
return_tensors="pt",
padding=True).values()
idx = attn_mask.sum(dim=-1) - 1
assert torch.all(idx >= 0), "Attention mask has zeros, empty suffixes"
suffix_tokens = suffix_tokens.to(device)
attn_mask = attn_mask.to(device)
idx = idx.to(device)
return TokenizedSuffixesResult(
input_ids=suffix_tokens,
attention_mask=attn_mask,
indices=idx
)
You prepend 🌍, knowing now that the tokenizer will slap on a space character ▁ and then tokenize
the result. ▁🌍 is not in the vocabulary, but both ▁ and 🌍 are, and there are no other strings in the vocabulary
that contain 🌍 as a substring. This forces the tokenizers hand, as the only possible valid tokenization is 29871, 31494,... followed by the rest of the tokens that correspond to the string, without the pesky leading space to mess things up.
Then, just slice out first two columns of spaces and 🌍’s!
God help me.
Very obviously, the tokenizer should not silently add a space character, especially when it’s not standard behaviour and other tokenizers (even the ones for Llama-3!) don’t act this way. If there’s no space, I can easily prepend one before tokenizing, but I can’t add a “negative space” to cancel out the one that’s there!
-
A technique where you cache the activations between every transformer block on a forward pass, and then feed each activation into the final layernorm and unembedding matrix to get an approximation of the logits for each token. This allows you to peek at what the model is “thinking” about at each layer mid-forward pass. ↩
-
The space is important, as the tokenizer for
llama-2likes to encode words with a leading space character, and I need to account for that. ↩ -
The pre-softmax activations that are output from the final layer of the model. ↩
-
yes, the literal emoji 🌍 ↩
-
No, not even other rotations of the earth emoji, like 🌎 or 🌏. It has to be 🌍. ↩